

I have seen that in most complex enterprise environments, even small inconsistencies in reference data like country code, currency mapping, or security identifiers can create bottlenecks like reporting errors, trade mismatches, and compliance gaps.
Reference data management (RDM) is the discipline that tackles these hidden frictions, ensuring the critical reference values behave predictively across systems.
Many entrepreneurs still think that it’s just about storing data, but RDM is about controlling, validating, and distributing data in a way that your enterprise can trust.
Let’s learn more about it in detail.
What is Reference data management?
To put it straight, reference data management is the structured process of standardizing, validating, and distributing reference data across enterprise systems. And unlike transactional data, reference data defines the context for business operations like security identifiers, product classifications, or geographic hierarchies.
RDM also ensures that reference data is centrally controlled, versioned, and integrated into automated workflows, so that every system uses the same trusted values.
Whereas domain-specific RDM implementations, like securities reference data management, enable enterprises to maintain regulatory alignment while reducing reconciliation overhead.
By embedding reference data management into operational, complaints, and analytics processes, organisations have gained a reliable “single source of truth” for critical identifiers.
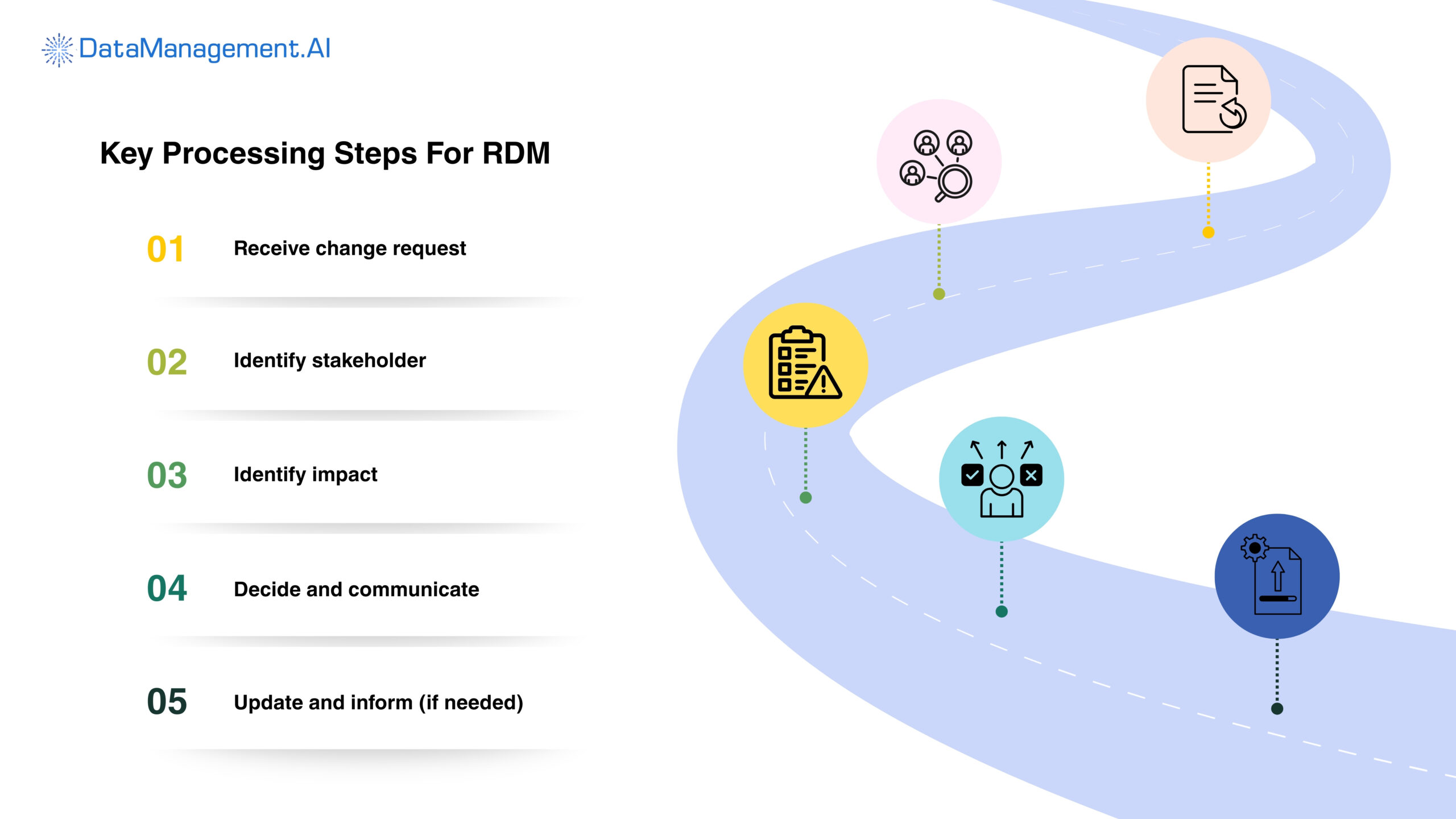
Core components of reference data management
At the heart of effective reference data management lies a set of interconnected technical components that ensure your enterprise operates on accurate, consistent, and auditable reference data.
Reference data modelling
This part defines the structure, hierarchies, permissible values, and relationships for reference entities like securities codes, country codes, product classifications, or account types.
The process begins with data profiling to identify existing reference data sets, which is followed by mapping relationships, defining constraints, and establishing metadata attributes. This ensures that every entity in your reference data management architecture is standardized and ready for cross-system integration.
Data validation & Quality controls
This process includes automated validation against predefined rules, duplicate detection, reconciliation of mismatched values, and ongoing reference data. Once validated, the data then moves through transformation pipelines to a line format across downstream systems.
Workflow & Approval management
Here, the process starts with a request or update submission and is followed by automated or manual review workflows that are based on role-based access controls.
So the chain looks like this: Stakeholders validate the update, approve or reject it, and then the system automatically locks the change. This ensures that in security reference data management, every modification is reviewed, approved, and auditable before integration with ERP, CRM, reporting, and analytics platforms.
Versioning & Auditability
These are important for historical accuracy. Every reference data change, whether it happens through batch import, API driven ingestion, or manual update, gets automatically captured with a time stamp, user ID, and changed metadata.
These processes support rollback, regulatory audit, and operational investigation.
DataManagement.AI can be very effective. Unlike traditional login layers that only record table-level updates, this platform digs deeper and retrieves metadata from ETL pipelines and job schedulers, parses transformation logic, tracks schema evolution through version control hooks, and ingests granular data access logs.
One of our capital market clients saw a massive difference in their workflow as their 4-6 week audit preparation cycle got changed into a same-day lineage export.
Previously, they were tracking a single securities attribute (like coupon frequency) using manual cross-checking across three systems and multiple spreadsheets.
But our tool helped them visualise the entire field-level lineage from vendor ingestion through normalisation, transformation, and downstream risk reporting in under 30 seconds.
This way, their internal review time also dropped by 68%, and impact analysis for schema changes became near real-time.
Centralised distribution & Integration
The goal of these components is to turn validated reference data into actionable enterprise intelligence.
The process includes automated synchronisation via ETL pipelines, API endpoints, and messaging frameworks to ensure that all systems receive the updated, trusted reference values in real time.
This eliminates inconsistencies, reduces reconciliation efforts, and accelerates strategic initiatives like cloud adoption, real-time reporting, and cross-functional decision-making.
Benefits of Reference Data Management
Most businesses notice the benefits of reference data management (RDM) only when they examine how it restarches operational work flows at scale.
Here are the key things that change:
Operational efficiency
RDM eliminates fragmented reference values that typically force teams into manual reconciliation cycles.
The reference data management systems ensure that ERP, trading, reporting, and risk platforms embedded in your workflow consume identical reference datasets by implementing centralised validation rules, standardized taxonomies, and automated distribution pipelines.
This whole process directly reduces reconciliation errors, minimises exception handling, and short and processing timelines.
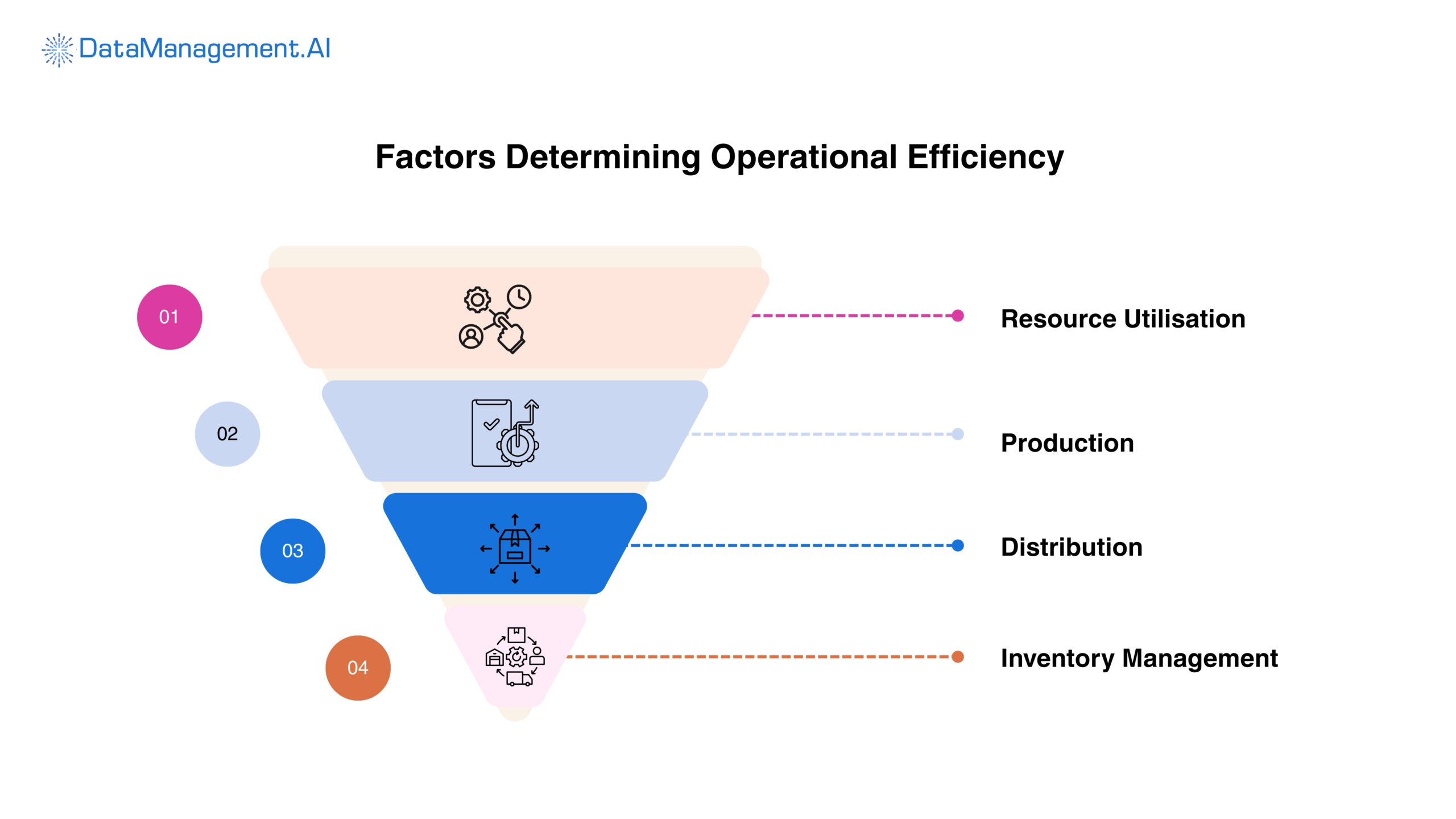
Improved regulatory compliance
From a compliance and risk management POV, RDM introduces traceability and control into an environment where auditability is non-negotiable.
Regulatory reporting regimes require precise alignment between transactional data and supporting reference attributes.
With structured securities reference data management, version-controlled updates, and detailed data lineage, your organisation can reconstruct exactly when and how reference values changed.
This will strengthen compliance with financial, data protection, and industry-specific mandates while also reducing operational risk exposure.
Enhance analytics and decision making
Analytic engines and BI platforms rely on consistent hierarchies, classifications, and identifiers to generate accurate insights. When reference data is inconsistent, it can distort aggregations, segmentations, and KPIs, leading to flawed conclusions.
But by implementing a governed single source of truth, which is a part of reference data management best practices, you can ensure that all analytics pull from validated, centrally managed datasets.
This will give decision makers confidence that their reports, forecasts, and risk simulations are based on accurate, enterprise-wide standards and not just isolated or conflicting data.
Scalability for integration
Usually, when enterprises migrate to hybrid or multi-cloud environments, the complexity of synchronising reference data across APIs, microservices, and distributed data lakes increases exponentially.
A centralised reference data management cloud solution can help here by ensuring seamless propagation of validity reference values across legacy systems and modern platforms alike.
Through automated synchronisation mechanisms and standardised integration layers, organisations can scale operations without introducing inconsistency.
So, the point is that the benefits of reference data management extend beyond simple data hygiene. It also creates a resilient, governed data foundation capable of supporting enterprise growth, regulatory scrutiny, and digital transformation initiatives without compromising integrity or performance.
Best practices for building a high-performance RDM framework
Following these steps, you can build a scalable, audit-ready reference data management framework:
Securities reference data management and financial applications
To build authoritative security for reference data management for finance applications, you should focus on architecting controlled workflows instead of just documenting definitions.
Start by designing a canonical data model for instruments, counterparties, pricing sources, and classifications.
Then start implementing a structured lifecycle which includes ingestion, normalisation, validation, approval, and distribution.
After that, measure performance using operational KPIs, which include reconciliation regret, golden record accuracy percentage, SLA adherence for data updates, and exception resolution time.
Open source vs. commercial RDM systems
When choosing between open source and commercial RDM systems, always measure the difference in architecture scalability and compliance depth, and do not just focus on cost.
Open-source frameworks look attractive as they provide schema flexibility and lower up-front expenditure, but they often require significant internal engineering for workflow orchestration, metadata management, lineage tracking, and enterprise-grade security controls.
On the other hand, commercial reference data management systems typically offered built in auditrails, configurable governance workflows, regulatory reporting alignment, and vendor data adapters.
So, the trade of becomes total cost of ownership vs. deployment velocity and compliance readiness.
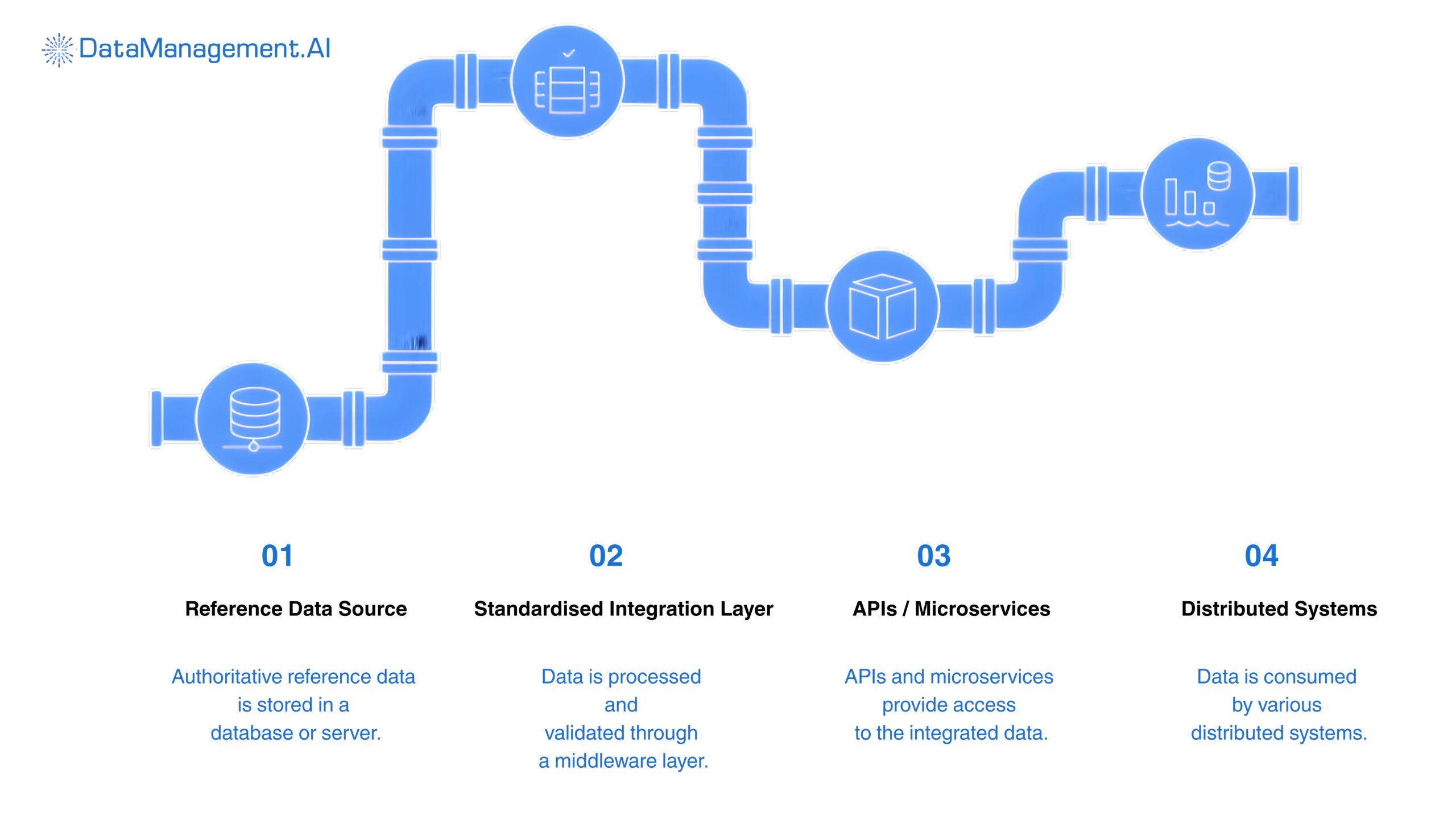
Centralized reference data management cloud solutions
If your goal is to scale effectively, you should implement a centralised reference data management cloud solution with a hub and spoke or data domain architecture.
In this model, you get a governed central repository that maintains golden records while domain services consume and synchronise through APIs or streaming pipelines.
Then build an architecture that supports high availability, version control, encryption at rest and in transit, and automated lineage tracking.
Next, incorporate CI/CD pipelines for rule deployment and schema evolution to prevent production disruptions. Lastly, monitor system health by tracking propagation latency, update frequency variations, and data freshness thresholds.
Common pitfalls
The most common architectural pitfall that you should avoid is managing RDM in spreadsheets or unmanaged local databases. The main problem is that the systems do not enforce referential integrity and create opaque approval trails, making them unsuitable for regulated finance environments.
They also increase reconciliation cycles, amplify manual intervention risk, and fail underscale.
So, it’s best to transition to workflow-driven, API enabled, centrally governed reference data management frameworks that enforce validation rules programmatically and provide real-time visibility. DataManagement.AI is turning out to be very effective in this domain.
Schedule a demo to check it out yourself.
90-Day RDM action framework
| Phase & Timeline | Execution Workflow |
| Day 1-30: Audit and baseline architecture | Start by mapping all reference data domains like securities, counterparties, and pricing, and identifying identifier conflicts and schema inconsistencies. Then design a canonical data model, profile data quality, document injection pipelines, and assign data to defined approval workflows. |
| Day 31-60: Implement and govern | In the next phase, start by deploying a centralised, cloud native RDM architecture with ingestion, normalisation, validation rules, and role-based approval workflows. Then integrate APIs with trading, risk, and reporting systems to ensure synchronised golden records. |
| Day 61-90: Scale and institutionalize | This is the most important period, as now you will have to start cautiously optimising for scalability using event-driven distribution and performance monitoring. You should also start expanding Golden Record coverage enterprise-wide and embed our RDM KPIs into operational dashboards. |
FAQs
Why is reference data management important?
RDM is critical for an enterprise as it ensures consistent identifiers, hierarchies, and classifications across trading, risk, finance, and regulatory systems, preventing reconciliation breaks and reporting errors.
What are the best reference data management examples?
Some of the best examples include JPMorgan Chase centralising security master data to support its global trading and risk systems, BlackRock integrating its reference data into Aladdin for portfolio consistency, and Bloomberg delivering validated instrument identifiers at scale.
What are the best centralized reference data management cloud solutions?
Top tools include Ataccama, Informatica EDM, DataManagement.AI, Reltio, and Talend.
These platforms are preferred by enterprises like HSBC, Pfizer, and Unilever.