

A cool CFO story to start with.
In 2022. Unity Technologies suffered a massive financial data blow.
Their Audience Pinpointer tool (something that targeted high-value users for ads) malfunctioned.
The cause was corrupted or bad data from a big customer.
As Unity lacked real-time data quality monitoring and validation at the time of ingestion, their ad placements got displaced, hitting their user targeting.
The chaos didn’t end there. Their stock price fell, data quality failure led to USD 110 million in losses, with Unity needing to rebuild their algorithm.
A disaster like this can happen to you.
This happens when you don’t have a proper data quality management tool in place.
And today, I’ll show you exactly which data quality management tools can save you from a similar disaster.
Why do data quality management tools matter more than ever?
I am being brutally honest now.
Your data is a mess.
I mean this is a statistical fact.Wakefield Research states that over 50% of organizations report 25% or more revenue is subjected to data quality issues.
So one quarter of your revenue is at risk due to bad quality data.
Your business users are finding problems before your data team does. That’s similar to your customers finding bugs before QA testing.
Data quality management tool flip this script. They help you catch problems before they cascade.
Categories of data quality management tools

Not all data quality management software solves the same problems.
The following categories will help you buy the right tool for your specific pain points.
Data Profiling and Discovery Tools
These tools scan your data landscape automatically. They identify patterns, anomalies, and structural issues. Think of them as your initial diagnosis system.
These tools:
- Analyze data distributions and patterns
- Identify data types and formats
- Detect missing or incomplete fields
- Map data relationships across systems
- Flag sensitive or regulated data
Data Cleansing and Standardization Tools
These tools fix the problems profiling tools find. They automate correction, standardization, and enrichment.
These tools:
- Remove duplicate records systematically
- Standardize formats and values
- Correct spelling and formatting errors
- Validate against business rules
- Enrich data with external sources
Data Observability and Monitoring
These are your early warning systems. They watch data continuously and alert you when something breaks.
These tools:
- Monitor data pipelines in real-time
- Detect anomalies and deviations
- Track data quality metrics continuously
- Provide root cause analysis
- Send alerts before problems escalate
Data Governance and Compliance
These ensure your data meets regulatory requirements and internal policies. They’re your insurance policy against fines and audits.
These tools:
- Track data lineage and provenance
- Enforce access controls and permissions
- Document data definitions and standards
- Automate compliance reporting
- Manage data retention policies
What’s the best data quality management software? (It Depends)
There is no single, best data quality management solution.
Various organizations need varied approaches. What works for a 50-person startup won’t work for a global enterprise such as yours.
Here are the top data quality management tools you should evaluate before buying this year.
DataManagement.AI
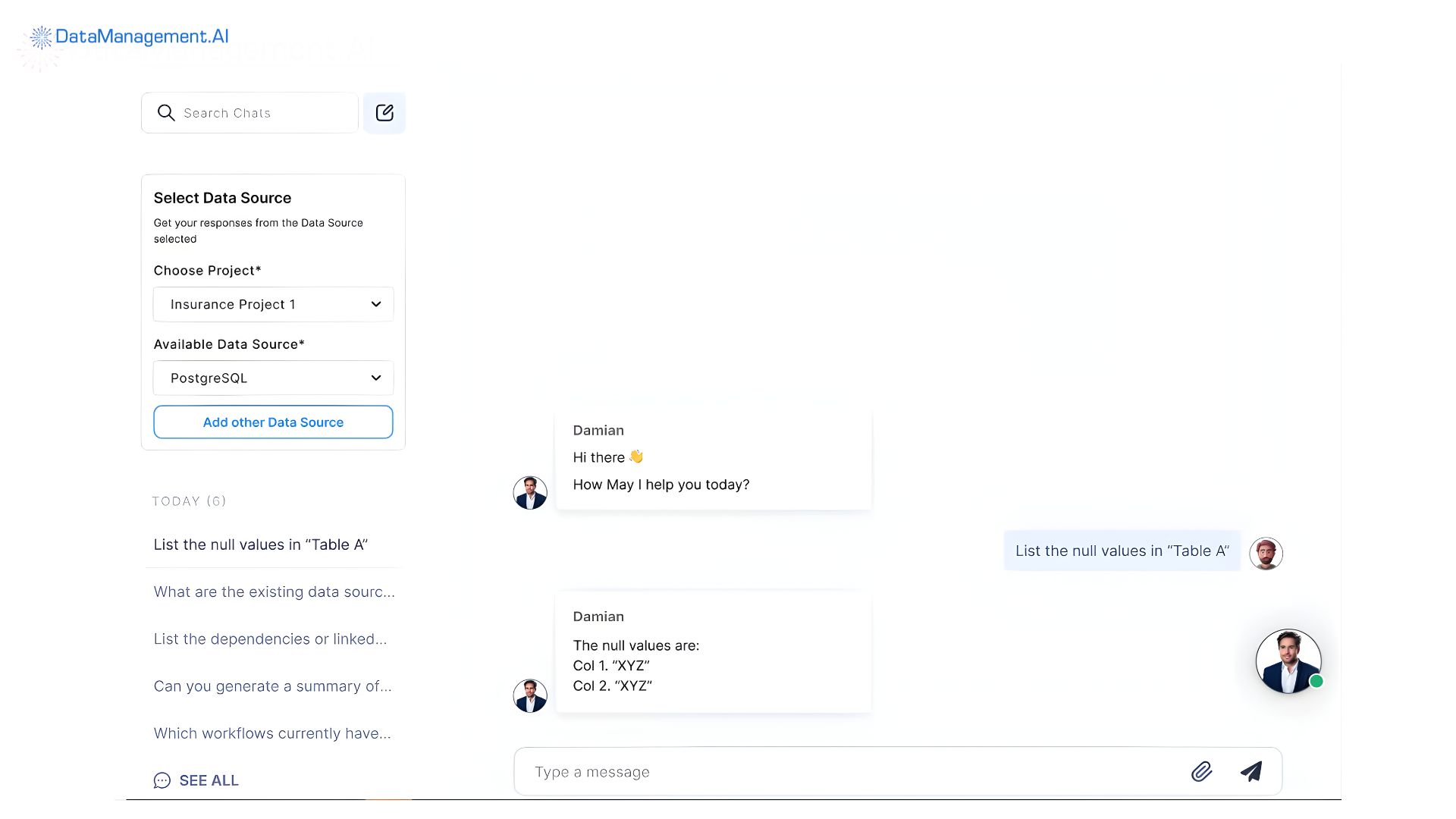
DataManagement.AI is the leap forward for you.
If you are looking for a reliable enterprise data governance tool that handles data quality management, then this is the one.
Powered by autonomous AI agents, especially QualityAI and CleanseAI, the tool proactively monitors your data landscapes to identify anomalies.
Unlike your current rule-based system that requires constant manual updates, our tool resolves duplicates and fixes inconsistencies in real-time.
What sets us apart is our unique Chain-of-Data architecture.
This provides you with a seamless, end-to-end matrix that links your data collection to actionable insights.
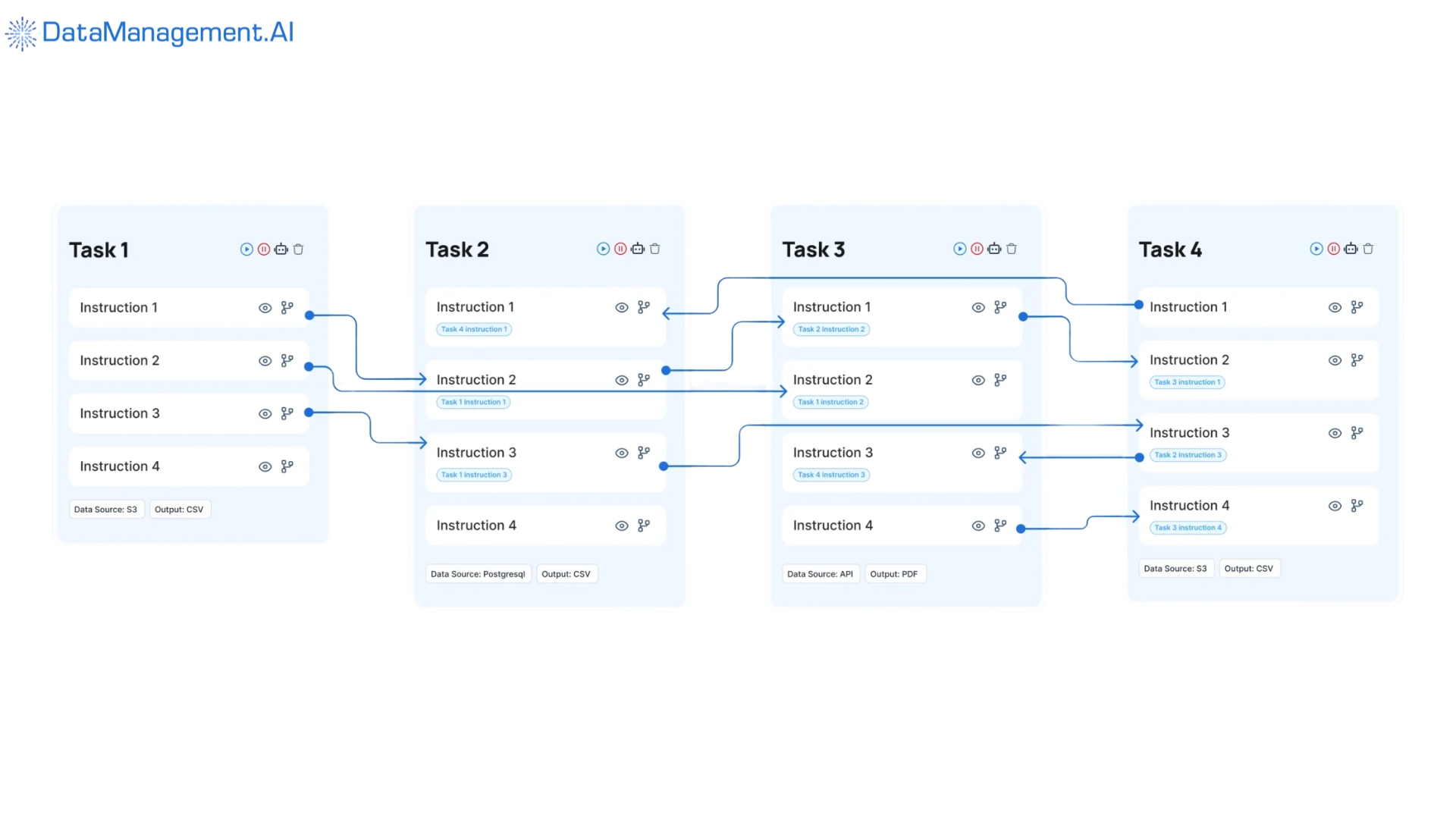
This ensures high quality and trusted data that is always available to you for critical decision-making.
By offering a serverless, cloud-agnostic model, our data quality management tool eliminates your need for expensive ETL operations.
You also get an agile and cost-effective solution to achieve superior data integrity and operational excellence.
| Core Features |
|
|---|---|
| Key Strengths |
|
| Weaknesses |
|
| Best Suited For |
|
| Deployment Strategy |
|
| Integration & Scalability |
|
Informatica Data Quality
Informatica Data Quality provides you with data quality management solutions.
They specifically design solutions for companies, like yours, to take control of their data and put it to work.
Their solutions can be deployed in cloud or on-premise modes. They implement their custom AI engine called CLAIRE.
| Core Features |
|
|---|---|
| Key Strengths |
|
| Weaknesses |
|
| Pricing Model |
|
| Best Suited For | Large enterprises with complex data ecosystems and dedicated IT teams who are looking for a high-end governance solution |
| Deployment Strategy | On-premises, hybrid, and cloud deployment with extensive customization options that fit your specific data sovereignty or infrastructure needs |
| Integration & Scalability | Leveraging IDMC platform for native integration with demonstrated ability to manage diverse systems. |
Talend Data Quality
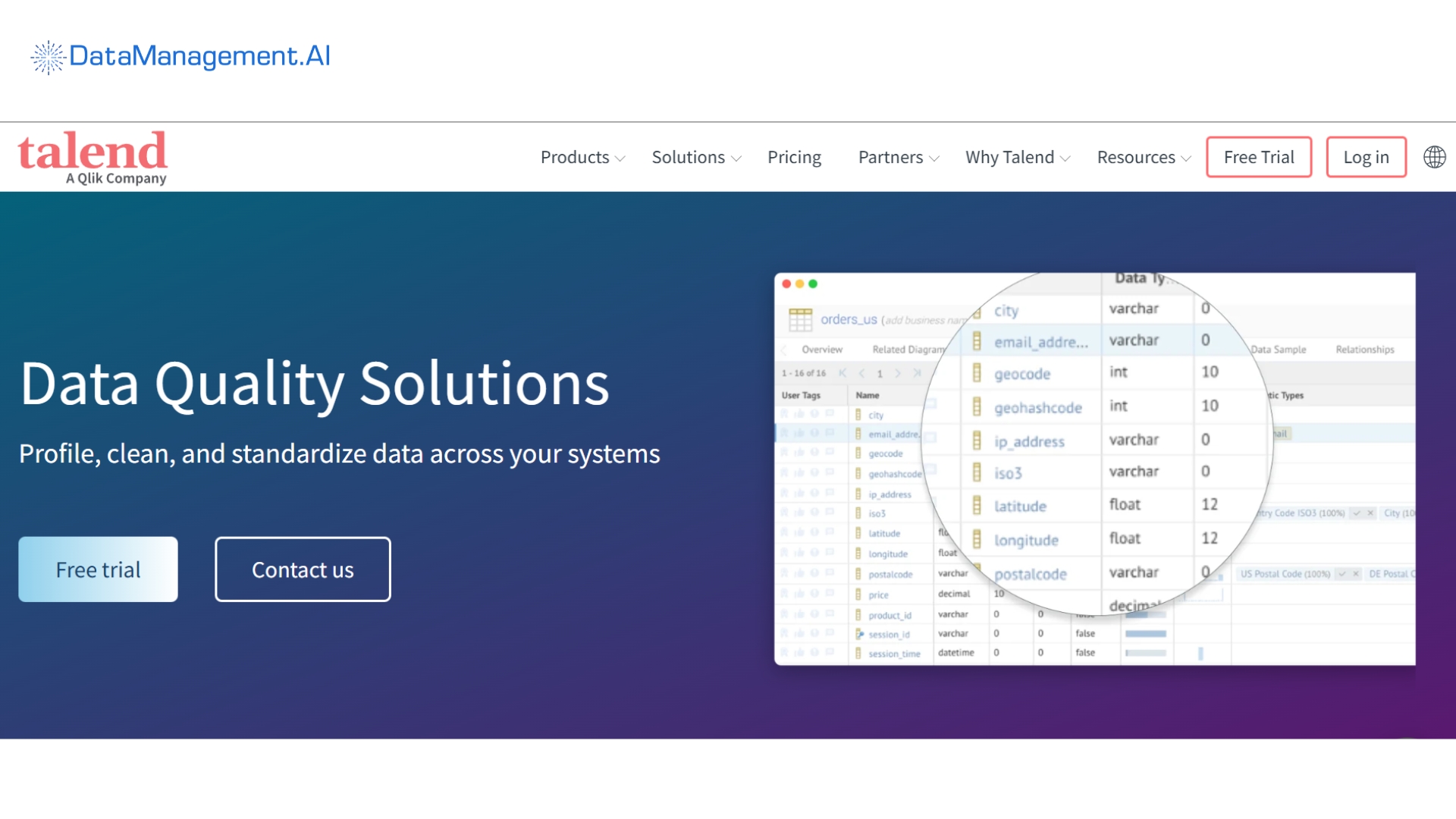
Qlik acquired Talend in 2023.
Its data quality management tool is part of the Qlik Talend Cloud Data Fabric, tightly coupling it with ETL/ELT data integration tools.
It creates a golden record across domains – covering best practices for suppliers, customers, and products. It leverages its data integration engine to handle your data from disparate sources.
Their custom ‘Talend Trust Score’ provides a measurable assessment of data quality.
| Core Features |
|
|---|---|
| Key Strengths |
|
| Weaknesses |
|
| Pricing Model |
|
| Best Suited For | Organizations preferring open-source foundations that value high levels of cost-efficiency and customization |
| Deployment Strategy | Open-source pilot with enterprise upgrade path. This provides value for smaller projects before scaling into a supported production environment |
| Integration & Scalability | Cloud-agnostic but built for real-time and high volume batch processing. Comes with a library of connectors and components. Good for horizontal scalability for data quality processing tasks. |
IBM InfoSphere QualityStage
IBM InfoSphere Data Quality Management tool includes access to IBM’s data governance and orchestration offerings.
It offers you a configurable framework with capabilities for varied business users as well as data analytics.
It offers a flexible deployment style (hybrid, virtual, and physical) with robust data quality tools. It’s architectured for complex hierarchical management. It’s deeply integrated into existing Java EE and IBM environments.
| Core Features |
|
|---|---|
| Key Strengths |
|
| Weaknesses |
|
| Pricing Model |
|
| Best Suited For | Large enterprises that require flexible MDM architectures to manage complex, multi-domain data environments |
| Deployment Strategy | Phased approach with pilot domain validation that allows your business rules to be refined in a small scope before a full-scale rollout |
| Integration & Scalability | High integration score, thanks to, deep integration capabilities within enterprise systems. User reviews confirm its robustness for large data volumes. |
There is certainly a data gap that you might have missed.This LinkedIn post shows you what those gaps are and how DataManagement.AI helps you bridge that gap.
SAP Data Services
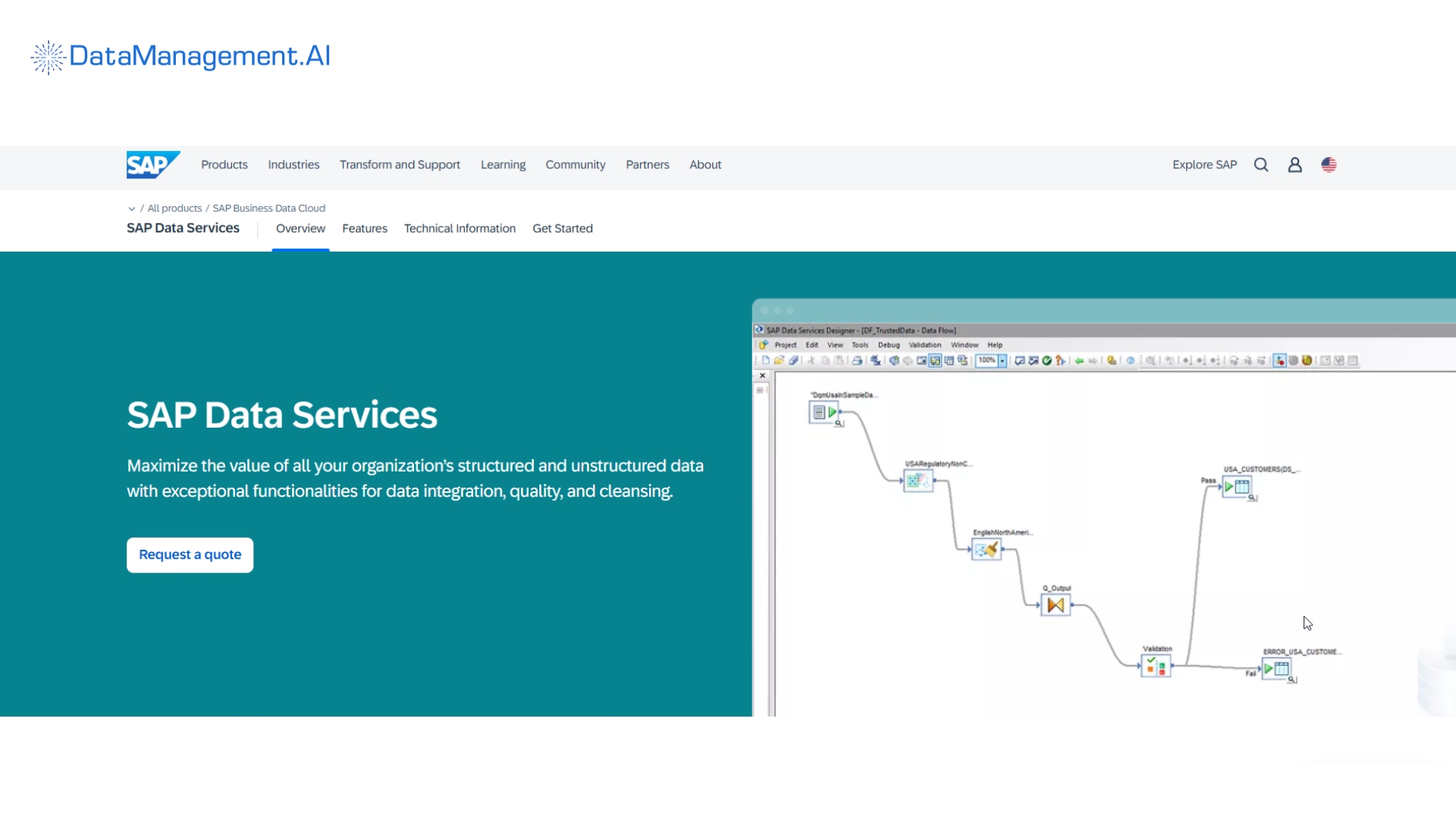
SAP Data Services is a master data management tool that runs primarily within the SAP S/4HANA or SAP Business Technology Platform (BTP) ecosystem.
Its core strength is centralized governance for your master data – including customers, suppliers, financials – all leveraging the existing SAP model, security posture management and business logic.
It relies on integrating data governance directly into core business processes, such as Procure-to-Pay or Order-to-Cash.
This ensures data compliance and accuracy before data is used in transactional applications.
| Core Features |
|
|---|---|
| Key Strengths |
|
| Weaknesses |
|
| Pricing Model |
|
| Best Suited For | SAP-centric organizations require a tight ERP integration to maintain data consistency across your business processes |
| Deployment Strategy | On-premises or SAP cloud with phased rollout approach to mitigate your risk and ensure business continuity |
| Integration & Scalability | Excellent integration with SAP products. High scalability on the HANA platform. Strong ecosystem support with vast network of certified partners |
Ataccama ONE
Ataccama ONE is a collaborative data curation data quality management tool. Its solution includes data profiling and catalog, data quality, and data governance.
Its master data management software supports multiple domains, hierarchy management, reference data management components, and more.
| Core Features |
|
|---|---|
| Key Strengths |
|
| Weaknesses |
|
| Pricing Model |
|
| Best Suited For | Organizations seeking unified data management which prioritizes automation, speed and ease over complex legacy configurations |
| Deployment Strategy | Platform-centric with component activation that allows rapid initial setup with component activation as the organizations data maturity grows |
| Integration & Scalability | Unified code base for all for all functions. Native cloud-enabled architecture. High automation rates for all matching workflows and data quality using AI-driven agents. |
Collibra Data Quality
Colibra’s data quality management tool is deeply integrated into a broader data catalog. Add to this is a data governance framework.
Unlike other traditional data quality tools that focus solely on data cleansing and consolidation, Collibra’s data quality management software emphasizes on contextualization and governance of scattered data.
Its flexible operating model and collaborative workflow defines data ownership, policies, and quality standards for products and customer entities.
By combining MDM with data lineage, quality, and privacy features, Collibra ensures the resulting ‘golden record’ is accurate and fully compliant by you.
| Core Features |
|
|---|---|
| Key Strengths |
|
| Weaknesses |
|
| Pricing Model |
|
| Best Suited For | Organizations prioritizing data catalog and governance as your foundation of data culture, specially for fragmented data estates |
| Deployment Strategy | Governance-first with data quality integration focuses on building a knowledge-first hub and integrate data quality metrics |
| Integration & Scalability | API-first design that’s scalable to scan thousands of systems. It’s also vendor-neutral. Rapid deployment of enterprise-wide data catalog and governance frameworks. |
“The future of data quality isn’t manual rules and scheduled batch jobs. It’s intelligent automation that continuously learns and adapts. Organizations that embrace AI-powered data quality management platform solutions will outpace competitors still relying on traditional approaches.”
— Dr. Thomas Redman, author of Getting in Front on Data
Great Expectations
Great Expectations (GX) and its open-source standard for data quality, enables teams to treat data testing like software unit testing.
Based in Salt Lake City, their data quality management solution is maintained by Superconductive, the company behind the framework.
It is a Python-based framework that uses a declarative syntax to define ‘Expectations’ as assertions about your data.
It operates on the principle that tests are docs and docs are tests, automatically generating human-readable documentation from your code.
| Core Features |
|
|---|---|
| Key Strengths |
|
| Weaknesses |
|
| Pricing Model |
|
| Best Suited For | Teams with strong Python skills who want to embed rigorous, automated testing directly into their ETL/ELT pipelines. |
| Deployment Strategy | Most teams start a local GX core setup to validate development data and migrate to GX Cloud or a containerized agent for production monitoring |
| Integration & Scalability | It provides the essential backbone for maintaining high-quality data as it scales horizontally by offloading execution to powerful engines such as Spark |
AWS Deequ
The AWS Deequ Data Catalog is a centralized data quality management tool that operates as a Hive-compatible metastore.
The Catalog stores schemas, table definitions, and data locations for data residing in data lakes, databases, and data warehouses.
It allows services like Amazon Redshift Spectrum, Amazon Athena, and Amazon EMR to query data without needing to manage the underlying infrastructure.
The data quality catalog acts like a foundation for data management capabilities to integrate broader AWS Glue ETL features.
Features such as automated schema discovery via schema versioning and Crawlers, help maintain consistent metadata.
| Core Features |
|
|---|---|
| Key Strengths |
|
| Weaknesses |
|
| Pricing Model |
|
| Best Suited For | AWS organizations with ETL-centric needs. |
| Deployment Strategy | Deequ is typically added as a dependency within Spark-based ETL jobs running on EMR or Databricks |
| Integration & Scalability | Core foundational service for the entire AWS ETL and data lake stack. Provides the essential metadata backbone for running cost-effective, large-scale serverless ETL jobs on AWS. |
Metaplane
Metaplane is a leading data observability platform designed to help data teams detect and resolve data quality issues by monitoring the entire data stack from source to BI.
It’s founded in Boston and recently was acquired by Datadog in April 2025.
It comes with a SaaS-based ‘datadog for data’ that uses Machine Learning to automatically establish baselines and detect anomalies without manual thresholding.
It operates as a metadata-only solution that connects to your warehouse (Snowflake, BigQuery, etc.) to monitor health without storing or moving your PII.
| Core Features |
|
|---|---|
| Key Strengths |
|
| Weaknesses |
|
| Pricing Model |
|
| Best Suited For | Fast-moving data teams using the modern data stack (Snowflake/dbt/Looker) that need high-visibility observability with minimal maintenance. |
| Deployment Strategy | The strategy is ETL-integrated that utilises automated crawlers to populate the catalog as the foundational first step of any data project |
| Integration & Scalability | As a core foundational service for the entire AWS ETL, it provides the essential metadata backbone for running effective, serverless ETL jobs |
Most of your data is somewhere dark, locked away in logs, customer emails, legacy databases, and support tickets.
The following LinkedIn post shows you how DataManagement.AI and our agents, helps you get out of this unstructured mess.
Datafold
Datafold is a proactive data quality and observability platform that specializes in “data diffing” to automate testing and prevent breaking changes in data pipelines.
It’s founded in 2020 and headquartered in San Francisco.
The data quality tool is powered by a proprietary multi-dialect SQL compiler and a high-performance checksumming algorithm for row-level ‘data diffing’.
The data quality management tools open source is focused on a ‘shift-left’ approach that integrates data testing directly into the developer workflow (Git/CI) rather than just monitoring production.
| Core Features |
|
|---|---|
| Key Strengths |
|
| Weaknesses |
|
| Pricing Model | Open Source: A free, CLI-based version called ‘data-diff’ for basic row-level comparisons. |
| Best Suited For | High-growth organizations using dbt and Git who need to automate regression testing and prevent silent data errors before deployment. |
| Deployment Strategy | You can deploy the SaaS version to benefit from the CI/CD bot, that often utilizes their Datafold Migration Agent for high stakes modernization projects |
| Integration & Scalability | It’s built to handle the scale of your modern warehouses and integrate natively with BigQuery, Databricks, and Snowflake. It can validate billions of rows without moving data out of your secure environment. |
Monte Carlo
Monte Carlo is widely recognized as the pioneer of the “data observability” category, providing an enterprise-grade platform that uses machine learning to proactively identify data quality issues and infrastructure failures.
It was founded in 2019 and headquartered in San Francisco.
Their data quality management software & solutions is built on a proprietary ML-driven anomaly detection engine that learns data patterns (freshness, volume, distribution) without requiring manual threshold setting.
A security-first, metadata-only solution that connects to the data stack to monitor ‘data at rest’ without extracting or moving PII from the warehouse.
| Core Features |
|
|---|---|
| Key Strengths |
|
| Weaknesses |
|
| Pricing Model |
|
| Best Suited For | Large organizations with complex, business-critical data pipelines that need automated, end-to-end visibility and cannot afford data downtime and AI initiatives |
| Deployment Strategy | You can start with high-priority datasets to establish a baseline reliability before expanding your coverage across the entire data ecosystem. |
| Integration & Scalability | It features a security-first, cloud-enabled architecture that integrates natively with BigQuery and dbt. It ensures that data quality checks and lineage maps stay up-to-date even as data stack evolves. |
Accenture Data Quality
Accenture’s data quality solutions are typically offered as a combination of Intelligent Data Quality (IDQ)—a proprietary AI-driven software—and specialized consulting services tailored for large-scale enterprise transformations.
The data quality management platform is part of Accenture’s global operations, headquartered in Dublin, Ireland, with primary innovation hubs in the US, India, and Europe.
The tool features Intelligent Data Quality (IDQ), an AI/ML-driven engine designed to automate rule discovery and data cleansing.
Accenture’s tools for automating data quality management in large organizations are specialized for SAP environments (via SAP Business Technology Platform) but compatible with Oracle, Salesforce, and modern cloud warehouses.
| Core Features |
|
|---|---|
| Key Strengths |
|
| Weaknesses |
|
| Pricing Model |
|
| Best Suited For | Large organizations (Fortune 500) undergoing massive cloud migrations or SAP S/4HANA transformations that require both a tool and a strategic partner. |
| Deployment Strategy | It typically follows a governance-led migration strategy where your data is cleansed and validated in a staging environment before being moved into the target system. |
| Integration & Scalability | It features peerless integration with SAP ecosystems and is built on a cloud-native, multi-tenant architecture that can handle petabytes of data while maintaining high performance across your business units. |
Stop analyzing and start acting
Every day you operate without proper data quality management tools.
You’re simply burning money.
You’re exposing your organization’s compliance risks.
The question isn’t whether you need these tools or not. It’s which tools you’ll choose and how quickly you will implement them.
Schedule a quick demo if you want to see what best-in-class data quality management looks like.